Introduction
In a retrieval Question Answering (QA) setting – also called Retrieval Augmented Generation (RAG), we first retrieve relevant information from a collection of texts and then feed it to a large language model (LLM). This can provide a form of long-term memory or domain adaptation for LLMs without the need for resource-intensive fine-tuning processes. In other words, the LLM does not simply guess the best answer based on what it has learned during training. Instead, the model combines newly retrieved information with its pre-existing knowledge to formulate an answer.
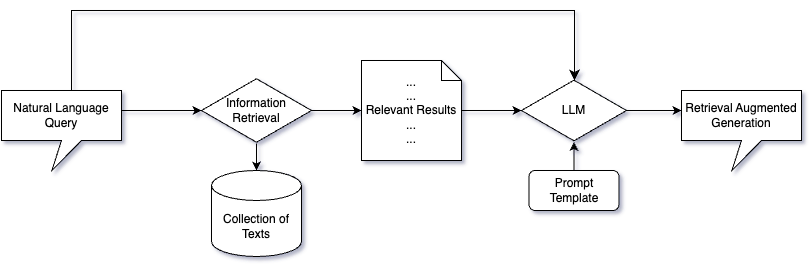
The method described not only provides users with the ability to validate the source of information used by the model, but it also reduces the likelihood of the model generating erroneous or unfounded information, known as “model hallucinations.” Furthermore, this approach can give users the capability to interact with a specific set of text data, or corpus, using natural language.
The recent surge in the use of vector databases has played a significant role in this context. Databases such as Pinecone, Weaviate or Chroma have grown in tandem with the rise of LLM-powered chatbots. These technologies have been praised for their efficiency and scalability, transforming how we handle and process large volumes of data. Yet, despite the increased attention directed towards vector database services, a critical aspect of this equation has received less consideration: the information retrieval (IR) approach itself.
This post aims to shed light on semantic search – a powerful component of IR. To clarify, semantic search is a methodology that not only identifies keywords in a user’s search query but also comprehends the context of the query, thereby enhancing the relevancy and precision of search results. We present our approach to constructing a carefully annotated dataset and assessing the effectiveness of multiple semantic search models. We primarily target the assessment of semantic search models’ efficacy on a collection of domain-specific documents. Ultimately, we aspire to discern the optimal approach for extracting the most pertinent information from similar corpuses.
Retrieving information that is relevant to a search query
Information Retrieval
Information Retrieval (IR) entails finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections. Retrieving pertinent information from a large pool of information system resources may either rely on full-text or content-based indexing. This can involve seeking information within a document, looking for the document itself, interpreting database content or identifying metadata that contains relevant information.
Term clarification
In this study, we focus on retrieval of textual data. We use the term document as a cover term for text of any length in a given collection, and the query for the user input of any length.
Assessing the performance of a search engine’s results
Regarding evaluation, it is heavily reliant on the nature of the problem at hand. In the context of retrieval QA, we are mostly interested in making sure that the top few results that are fed to the LLM consist of at least one retrieved document containing the answer to the user query, or multiple documents that, when combined, help provide such an answer.
nDCG@K
One of the popular IR evaluation metrics that can capture such features is the normalized discounted cumulative gain (nDCG@K), measured on the top K retrieved documents.
Considering a single query and a sequence of the most relevant documents retrieved, we can calculate the normalized discounted cumulative gain using relevancy score annotations for every query-document pair relk.
Cumulative Gain:
(1)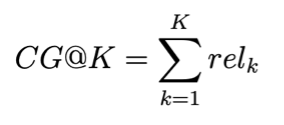
Discounted Cumulative Gain:
(2) ![]()
Normalized Discounted Cumulative gain:
(3)![]()
Where relk is the relevancy score of the k–th top answer (for example, a score from 0 to 5), and iDCG@k is the ideal discounted cumulative gain, meaning the DCG@k if the retrieved documents were ideally sorted by the search engine.
Semantic search with dense vectors
Semantic search
Sparse (1,2), late-interaction (3) and dense retrieval (4, 5, 6) methods are usually associated with semantic search. These methods focus on finding responses to a search query by understanding the searcher’s intent, the context of the given query and the relationship between words. Such an approach can alleviate the ambiguous nature of search queries and bridge the lexical gap that keyword-based methods are often unable to overcome without heavy text preprocessing. Furthermore, identical search queries could be phrased in diverse ways. Finally, semantic search also considers the relationship between words, which can be crucial to find relevant information.
Take, for instance, a scenario in which a user is searching for information about the “benefits of a Mediterranean diet”. A keyword-based approach would focus on documents containing these exact words. This approach might overlook important and relevant documents that use different terminology, such as “advantages of eating like a Greek”, or “positive health outcomes of Southern European food habits”. In contrast, a semantic search would consider synonyms and related terms, thus fetching information based on the true meaning of the search query.
Sentence-transformers
The unveiling of the BERT language model (7) paved the way for the introduction of an innovative derivative: the sentence-transformer (8). This new model was designed specifically for transforming text data into semantically nuanced vector representations. Building on the original BERT model’s transformative architecture, the sentence-transformer added a final mean pooling layer. During training and inference, this feature converts the collection of contextualized word vectors into a single, dense vector, rather than having an output tensor of individual word vectors, as the original transformer encoder does.
Turning text data into meaningful vector representations was not a new idea; word2vec (9) had already marked considerable progress in this field of NLP. However, word2vec’s representations were static, which meant that a word’s vector did not change based on its context or position within a sentence. Sentence-transformers improved upon this by accounting for context-specific meanings of words. For instance, the word “bank” should have different vectors when referring to the side of a river versus a financial institution.
By employing these context-dependent vectors, sentence-transformers can capture the semantic nuances of the same word used in different contexts. The model offers a more sophisticated textual encoding and a deeper understanding of sentence-level semantics, marking a departure from the earlier focus on individual words. This major stride forward has opened an array of new opportunities (including Unsupervised Topic Modeling), such as using these vectors for semantic search.
Sentence-transformers are open source, which means they’re freely available for use and modification as needed. They perform exceptionally well on a range of tasks, a fact that is supported by multiple published studies. Moreover, these models come with a comprehensive framework that allows domain adaptation and access to several powerful pre-trained models. Due to these advantageous properties, all the semantic search models evaluated in our study are sentence-transformers. Nevertheless, the presented methodology remains valid for all classes of semantic search models.
Methodology
Query selection
To select a set of queries that we will use to evaluate the performance of semantic search models, we can start by using a query generation model called T5 (10), which was trained on the MSMARCO dataset (11). This dataset includes queries from the Bing search engine and human-generated answers for each. When we run the model on a corpus of texts, multiple queries can be automatically generated for each document. We then select a subset of queries that cover a range of topics of interest. As a rule of thumb, 50 queries have been found sufficient to assess a search engine’s performance (12). This approach ensures the presence of at least one satisfactory answer in our corpus for each query.
Annotation Campaign
Once a set of queries has been selected, we retrieve the most relevant documents using different semantic search models and have domain experts rate the relevancy of each query-document pair. The relevancy score can either be binary or on a discrete scale (if we want to use typical IR evaluation metrics such as the nDCG). An ideal semantic search engine would output the k most relevant documents to a given query, sorted from most to least relevant.
Our annotation campaign is an iterative process. The first round involves model selection, where a couple of top-performing semantic search sentence-transformers are selected. We use models with varying transformer architectures (such as BERT, DistilBERT (13), or MPNet (14)) and which have been pre-trained on different IR datasets (such as MSMARCO). We also include a fine-tuned model using an unsupervised approach called GPL (15). The annotation guidelines are then refined based on feedback from the annotators. In a second round, we gather more annotations for models that appear to perform well on our corpus. These relevancy annotations are in turn used to calculate the nDCG (amongst other evaluation metrics), which enables us to compare the performance of those pre-trained semantic search models on our corpus. We also use these annotations to fine-tune a semantic search model using a supervised approach: Augmented SBERT (16). In a final round, this fine-tuned model’s answers are annotated for a completely new set of queries that the model has not seen during training.
Results on a corpus of Legal Documents
The methodology presented above was applied in the context of an application highlighting the power of semantic search on legal documents. The chosen corpus contains rulings from the Court of Justice of the European Union. Examples of query-document pairs can be found in the table below, with k indicating the k-th best answer.
| Model name | k | Query | Retrieved passage |
| multi-qa-mpnet-base-dot-v1 | 5 | What are the macroeconomic indicators? | The macroeconomic indicators are: production, production capacity, capacity utilisation, sales volume, market share, growth, employment, productivity, magnitude of the amount of countervailable subsidies, and recovery from past dumping or subsidisation. |
| msmarco-bert-base-dot-v5 | 4 | What measures should hosting service providers take to prevent terrorism? | Hosting service providers shall set out clearly in their terms and conditions their policy for addressing the dissemination of terrorist content, including, where appropriate, a meaningful explanation of the functioning of specific measures, including, where applicable, the use of automated tools. |
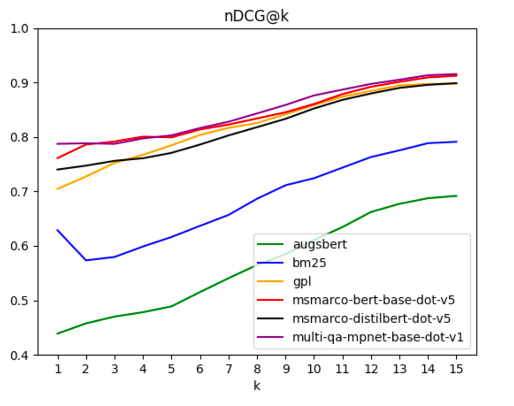
The nDCG on the top 10 results of each model is reported in the table below. We also included a simple lexical search using the BM25 algorithm with default parameters (17) as a baseline for comparison. The top-performing models were the pre-trained sentence-transformers. The GPL technique showed overall satisfactory performance but did not really surpass any of the pre-trained sentence-transformers. The supervised domain adaptation using Augmented SBERT led to the worst-performing model, suggesting a need for a larger set of queries (while more than 2000 unique query-document pair annotations were used for fine-tuning, these only contained 50 unique queries).

We also performed a sensitivity to k analysis. In the graph below, we see that for most values of k, the results remain consistent across models, which justifies reporting only values for k = 10.
Limitations and Future Work
Throughout our investigation, we stumbled upon several challenges that left their mark on our work. Firstly, despite our best efforts, the models that we refined in-house couldn’t surpass the results of the pre-trained models. This suggests that these pre-existing models are already highly optimized and leaving little room for improvement, at least with the fine-tuning techniques we applied.
Another challenge was in the application of Augmented SBERT for semantic search, which is still relatively unexplored territory. Particularly, we faced difficulties in creating a suitable training set due to a mismatch between its distribution and that of our corpus. This ‘distribution’ refers to two aspects: the diversity of topics and the proportion of relevant versus irrelevant answers to each query. In focusing on a limited number of queries and primarily incorporating the most relevant answers for each into our dataset, we may have underrepresented the corpus’s topic diversity and overlooked the inclusion of irrelevant examples potentially beneficial for fine-tuning.
The task of annotating relevancy on a scale from 0 to 5 also turned out to be quite subjective. An alternative approach could have been to use triplet annotations (comparing pairs of query-document combinations), which may have made the task easier for our raters (and better for fine-tuning). However, since we needed these labels for evaluation, we stuck with pair annotations.
Despite the challenges encountered, we remain enthused about the prospects our research holds. Our study has led to the creation of an extensive corpus of labeled query-passage pairs, offering a rich resource for future experimentation. We anticipate that fine-tuning using different loss functions and utilizing larger annotated corpora could bring forth promising results.
Moreover, we consider the GPL unsupervised domain adaptation technique to possess significant potential. We conjecture that it may emerge as the top-performing technique for corpora that originate from domains more divergent from the pre-trained models’ trainset than the legal domain. As we continue to navigate the uncharted waters of semantic search, we are excited to unravel the potential that lies ahead.
Conclusion
While our study acknowledges the challenges and limitations inherent in any research endeavor, we have honed our expertise in designing tailored information retrieval solutions. Our dedication to providing clients with actionable recommendations ensures that they can benefit from the synergistic integration of vector database services and chat based LLMs, empowering them to make informed decisions while streamlining their operations.
Join us as we share the outcomes of our research and continue pushing the boundaries of semantic search.
——————————————————————————————————————–
Resources :
- 1) R. Nogueira, W. Yang, J. Lin, and K. Cho, “Document expansion by query prediction.,” CoRR, vol. abs/1904.08375, 2019.
- 2) Z. Dai and J. Callan, “Context-aware sentence/passage term importance estimation for first stage retrieval.,” CoRR, vol. abs/1910.10687, 2019.
- 3) O. Khattab and M. Zaharia, “Colbert: Efficient and effective passage search via contextualized late interaction over bert,” in Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, (New York, NY, USA), p. 39–48, Association for Computing Machinery, 2020.
- 4) M. Li and J. J. Lin, “Encoder adaptation of dense passage retrieval for open-domain question answering,” ArXiv, vol. abs/2110.01599, 2021.
- 5) S. Hofstätter, S.-C. Lin, J.-H. Yang, J. Lin, and A. Hanbury, “Efficiently teaching an effective dense retriever with balanced topic aware sampling,” in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’21, (New York, NY, USA), p. 113–122, Association for Computing Machinery, 2021.
- 6) J. Ma, I. Korotkov, Y. Yang, K. Hall, and R. McDonald, “Zero-shot neural passage retrieval via domain-targeted synthetic question generation,” in Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, (Online), pp. 1075–1088, Association for Computational Linguistics, Apr. 2021.
- 7) J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), (Minneapolis, Minnesota), pp. 4171–4186, Association for Computational Linguistics, June 2019.
- 8) N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in EMNLP/IJCNLP (1) (K. Inui, J. Jiang, V. Ng, and X. Wan, eds.), pp. 3980–3990, Association for Computational Linguistics, 2019.
- 9) T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” Advances in Neural Information Processing Systems, pp. 3111-3119, 2013.
- 10) C. Raffel, N. M. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” ArXiv, vol. abs/1910.10683, 2019.
- 11) T. Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiwary, R. Majumder, and L. Deng, “Ms marco: A human generated machine reading comprehension dataset.,” CoRR, vol. abs/1611.09268, 2016.
- 12) C. D. Manning, P. Raghavan, and S. Hinrich, Evaluation in information retrieval. Cambridge University Press, 2019.
- 13) V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” arXiv preprint arXiv:1910.01108, 2019.
- 14) K. Song, X. Tan, T. Qin, J. Lu, and T.-Y. Liu, “Mpnet: Masked and permuted pre-training for language understanding,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, (Red Hook, NY, USA), Curran Associates Inc., 2020.
- 15) K. Wang, N. Thakur, N. Reimers, and I. Gurevych, “GPL: Generative pseudo labeling for unsupervised domain adaptation of dense retrieval,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Seattle, United States), pp. 2345–2360, Association for Computational Linguistics, July 2022.
- 16) N. Thakur, N. Reimers, J. Daxenberger, and I. Gurevych, “Augmented SBERT: Data augmentation method for improving bi-encoders for pairwise sentence scoring tasks,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Online), pp. 296–310, Association for Computational Linguistics, June 2021.
- 17) S. Robertson and H. Zaragoza, “The probabilistic relevance framework: BM25 and beyond,” Foundations and Trends® in Information Retrieval, vol. 3, no. 4, pp. 333– 389, 2009.