Context
In a world that constantly transforms and refines itself, businesses and their workforce need to stay in sync with the latest industry-related breakthroughs to remain competitive and innovative. Nevertheless, the rapidly growing stream of information poses a challenge when it comes to identifying and understanding key trends, events, or breakthroughs within each sector. One may find it overwhelming to distill large amounts of information unless one is prepared to sift through countless articles and posts.
Adding to this complexity, content often comes wrapped in a variety of languages from a wide range of sources. Emergent platforms, such as blogs, are consistently joining the ranks of traditional news outlets, adding to the burden of information distillation.
In response to the need to circulate industry-specific knowledge, several organizations use internal newsletters or specialized communication channels. In such setups, employees periodically share relevant articles, making them accessible to everyone. However, these methods are often rigid and time-consuming. More importantly, they can be biased, favoring the topics and sources preferred by the individual who shares the information.
Advancements in Large Language Models (LLMs) provide an elegant solution to this predicament. These state-of-the-art techniques enable the curation of newsletters to the unique needs and interests of specific business units or individual readers. This automated approach is not only streamlined and lightweight, but it also offers a more personalized approach to communicating information internally.
By harnessing the capabilities of LLMs, companies can shift from a ‘one size fits all’ approach to a custom and nuanced method of sharing updates. This can significantly enhance the efficiency of internal communication, eliminate biases inherent in traditional methods, and ensure that the right information reaches the right people at the right time.
Problem
The challenge of staying updated with the latest developments has triggered the adoption of LLMs to summarize written information or generate new text. One key factor in these models is the ‘context window’ – a term referring to the model’s ‘attention span’, or the number of tokens it uses to comprehend and generate its responses. Unfortunately, this context window can often be quite limiting.
Taking the example of ChatGPT Plus with GPT-4, the context window is approximately 32,000 characters. Meanwhile, the average article in its training dataset runs about 20,000 characters long. This implies that the model lacks the ability to process multiple articles simultaneously, thereby limiting its ability to provide summaries spanning numerous sources.
Adding to this constraint, there’s also the issue of a ‘knowledge cutoff’: ChatGPT’s knowledge is anchored to a specific point in time. In this case, it’s up until September 2021. As a result, the model is unable to provide any recent information.
So, while the use of ChatGPT (or another LLM) may seem like a magical solution, it has some limitations. Using these models effectively does not only require a robust framework for content creation, but also a solid understanding of how to utilize LLMs programmatically. It’s not a simple plug-and-play affair, but rather a tool that needs careful use, especially if it is to be employed in a setting where accuracy and recency of information are critical.
Solution
The creation of an internal newsletter leveraging the power of LLMs and techniques in Natural Language Processing (NLP), as previously discussed, follows a particular process.
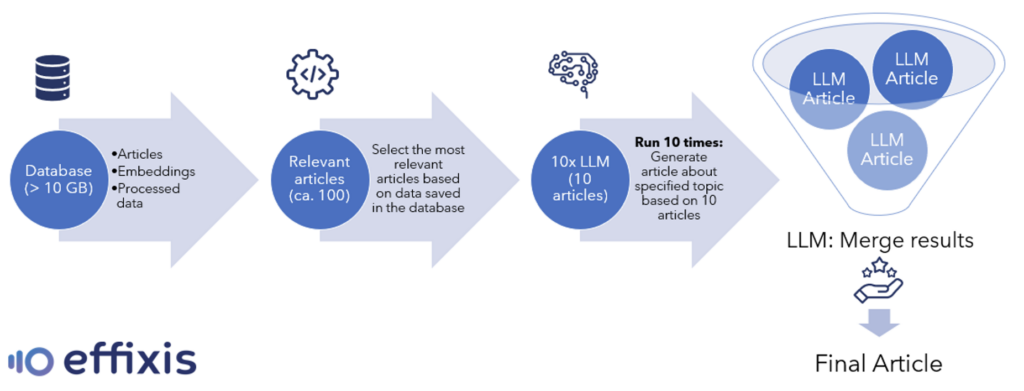
Our first requirement is a comprehensive and up-to-date database, consisting of articles sourced from a wide variety of outlets. This repository serves as the raw material from which we can extract the most relevant articles. To extract such articles, we can use a rudimentary keyword search or a more sophisticated semantic search, facilitated by vector databases. A more advanced technique might involve the application of categorization in NLP, as demonstrated in Effixis’ offerings like Intelligent Tagging.
Once we’ve collected the most relevant articles relating to a particular theme, LLMs with a large context window come into play. The task at hand is to prompt the model to create an entirely fresh article based on the curated selection. Let’s assume, for instance, that we have pulled 100 articles that resonate with our topic of interest after our search. The next step would be to feed the LLM, 10 separate times, to generate a new article. In each iteration, we present the model with a random subset of 10 articles out of the initial 100 selected.
Finally, we prompt the LLM once more, this time to weave the 10 generated articles into one consolidated piece. The result of this procedure is a brand-new, coherent article pertaining to the given topic, bearing the distilled knowledge of all the relevant articles. This approach enables us to create a customized internal newsletter that is both comprehensive and nuanced, drawing from a broad range of relevant sources and tailored to our specific needs.
Wait, is this an article — and not a newsletter?
Yes, you’re absolutely correct. The creation of a custom newsletter, particularly one aimed at a specific group of individuals, involves additional steps beyond just generating individual articles.
In our context, the envisioned newsletter would contain a series of articles. Consequently, the primary method of creating the newsletter relies on customizing the themes of these articles. This task of adapting something to fit a specific use case is typically accomplished through a process known as fine-tuning. This involves making minor adjustments to a pre-trained model to optimize its performance for a new application.
In our specific use case, where we’re tailoring the article topics to align with the reader’s role within the firm, this process of fine-tuning takes on a couple of different dimensions. Firstly, it involves fine-tuning the prompts based on the user role to ensure that the content generated is relevant and beneficial for the intended audience. Secondly, it entails the selection of pertinent topics for the article using an LLM, ensuring the content reflects the needs and interests of the readers.
In this way, the approach we’re discussing moves beyond the generation of standalone articles to a more holistic process of constructing a comprehensive, tailored newsletter, offering valuable insights and information to its intended audience.
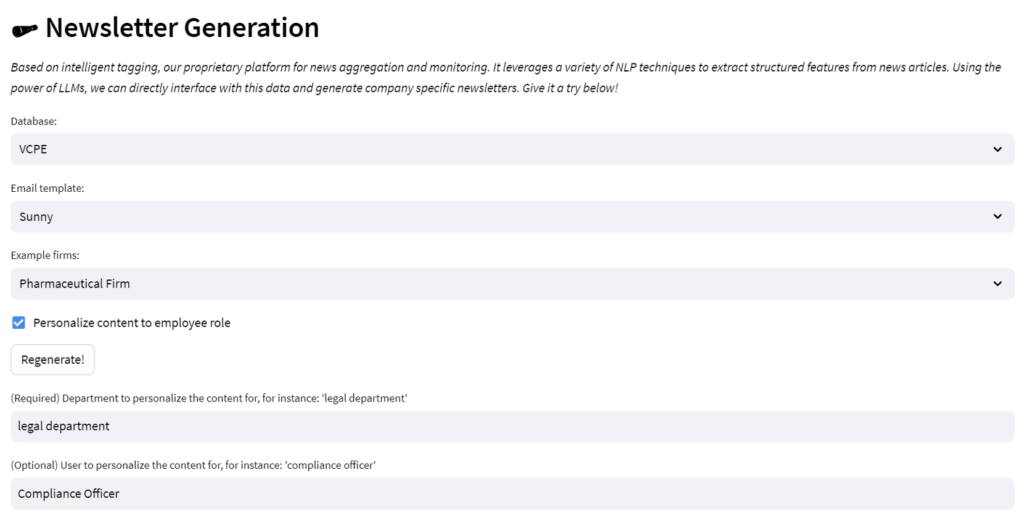
We also need to consider how we format and present the articles, be it in bullet point style or as structured paragraphs. We recognize the significance of aesthetic appeal and readability and thus offer an array of templates for users to select from for their newsletter. If these are not sufficient then a custom one can be created for the user. This gives users the freedom to shape the visual aspect and overall feel of the newsletter to suit the preferences of its intended recipient.
Imagine, for instance, we are crafting a newsletter on latest drug developments for a scientist within the R&D department of a pharmaceutical firm. The presentation of the content would likely vary dramatically from a newsletter intended for a marketing executive within the same organization. The scientist may prefer a more academic structure with clearly delineated sections and bullet points summarizing key findings, while the marketing executive might favor a more narrative, conversational style that emphasizes the implications of the research for marketing strategies. The availability of diverse templates and the user rule adjustments allows for this level of customization, helping ensure the newsletter’s format resonates with the reader’s role and preferences.
Here is a brief glimpse into what a section of a newsletter, tailored for a pharmaceutical scientist in a pharma firm, might look like:

Conclusion
When wisely deployed, LLMs and other NLP techniques can create newsletters that deliver pertinent insights to their target audience.
These tools can identify the reader’s areas of interest, discover articles that are highly relevant to each of these topics, and distill the key points. From there, we can reformulate this information into a new article, which we can present in a user-customized newsletter format – whether that’s in bullet points, key takeaways, and so forth. Beyond this, the solution also includes the maintenance of a database, ensuring it is consistently updated with the freshest information.
The outcome is a highly effective pipeline for distributing the latest and most relevant information – whether scientific articles, internal documents, or news stories – across all departments within an organization. This ensures that all employees, regardless of their role, have access to the information that is most relevant to them. It’s a crucial stride in maintaining the organization’s competitive edge, and in proactively upskilling employees, keeping them well-informed about the latest developments in their respective fields.
By contacting us, we invite you to take a look at a proof-of-concept newsletter, which has been generated using the process detailed in this article. Please note, however, that the data used for this demonstration may not be the latest. Additionally, firm and product names may have been altered or redacted to respect copyright considerations.